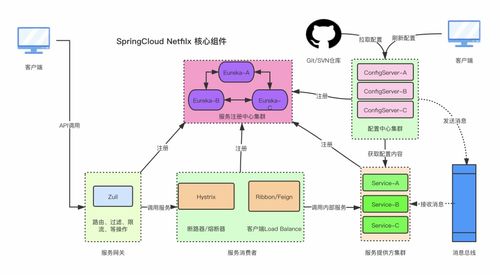
在微服务架构体系中,Spring Cloud作为业界广泛采用的治理框架,为分布式系统的构建提供了标准化解决方案。其中,数据处理与存储服务的设计与实现是微服务落地的核心环节,直接关系到系统的稳定性、可扩展性与数据一致性。本文将从架构模式、技术选型、数据治理三个维度,深入探讨Spring Cloud生态下数据处理与存储服务的实践策略。
一、数据服务的架构分层与解耦
微服务倡导单一职责与独立部署,数据处理服务需遵循领域驱动设计(DDD)原则进行垂直拆分。典型的数据服务架构包含三层:
- 数据接入层:通过Spring Cloud Gateway统一接入请求,配合Resilience4j实现熔断限流,避免数据洪峰冲击底层服务
- 业务处理层:基于Spring Boot构建独立数据微服务,每个服务独占数据库实例。采用Spring Data JPA/MyBatis Plus实现数据持久化,通过Feign Client进行服务间数据聚合
- 数据存储层:根据CAP定理进行存储选型,关系型数据库(MySQL/PostgreSQL)承载强一致性事务数据,NoSQL(MongoDB/Redis)处理高并发查询与缓存需求
二、分布式数据一致性保障机制
2.1 事务协调模式
- Saga模式实践:通过Spring Cloud Stream集成消息中间件(RabbitMQ/Kafka),将跨服务事务拆分为可补偿的本地事务。每个子事务完成后发布领域事件,触发后续服务执行,任一节点失败则触发逆向补偿操作
- TCC柔性事务:在资金交易等强一致性场景中,采用Seata框架实现Try-Confirm-Cancel三阶段提交,通过@GlobalTransactional注解声明分布式事务边界
2.2 数据同步策略
- CDC变更捕获:部署Debezium组件监听数据库binlog,将数据变更实时同步到Elasticsearch构建查询集群,解决跨服务数据关联查询难题
- 事件驱动架构:利用Spring Cloud Function实现数据变更事件的标准化处理,确保各微服务间的最终数据一致性
三、数据存储的弹性设计
3.1 多级缓存体系
// 基于Spring Cache的多级缓存配置示例
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public CacheManager cacheManager() {
CaffeineCacheManager caffeineCacheManager = new CaffeineCacheManager();
caffeineCacheManager.setCaffeine(Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.maximumSize(1000));
// 二级Redis缓存
RedisCacheManager redisCacheManager = RedisCacheManager
.builder(redisConnectionFactory)
.cacheDefaults(RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofHours(1)))
.build();
return new CompositeCacheManager(caffeineCacheManager, redisCacheManager);
}
}3.2 读写分离与分库分表
- 通过ShardingSphere-JDBC在应用层实现透明化数据分片,配合Spring Cloud LoadBalancer将读写请求路由到不同数据库实例
- 基于时间或业务主键设计分片键,避免热点数据问题,支持动态扩缩容
四、数据治理与监控体系
4.1 可观测性建设
- 集成Micrometer收集数据服务指标,通过Spring Cloud Sleuth实现全链路追踪,关键SQL执行耗时通过Tag标识
- 配置Grafana监控面板,实时展示数据库连接池状态、慢查询统计、缓存命中率等核心指标
4.2 数据安全治理
- 采用Vault动态管理数据库凭证,通过Spring Cloud Vault自动轮转访问令牌
- 敏感数据字段使用Jasypt进行加密存储,审计日志通过AOP切面统一记录数据访问行为
五、演进式架构实践案例
某电商平台订单数据处理服务演进路径:
- 单体阶段:所有订单数据集中存储于MySQL集群,通过读写分离支撑初期业务
- 服务拆分:按订单状态(待支付/待发货/已完成)拆分为独立微服务,每个服务使用独立数据库实例
- 能力增强:
- 订单查询服务引入CQRS模式,写库继续使用MySQL,读库迁移至Elasticsearch
- 支付流水数据采用时序数据库TDengine存储,支撑毫秒级交易数据分析
- 全局优化:部署Apache Pinot构建实时OLAP系统,支撑多维度订单数据即席查询
六、未来技术展望
随着云原生技术发展,Spring Cloud微服务的数据处理呈现新趋势:
- Serverless数据层:通过Spring Cloud Function对接云厂商Serverless数据库,实现按需伸缩的数据处理能力
- 数据网格架构:采用Data Mesh理念,将数据产品化,每个业务域团队自主管理其数据服务的全生命周期
- 智能数据路由:基于Spring AI集成预测模型,动态调整数据存储策略,如热数据自动缓存、冷数据自动归档
Spring Cloud微服务架构下的数据处理需要平衡一致性、可用性与扩展性。通过分层解耦设计、合适的一致性方案、弹性存储策略三位一体的架构规划,结合持续演进的数据治理体系,方能构建出既满足当前业务需求,又具备未来扩展性的稳健数据服务生态。