HBase作为分布式、面向列的NoSQL数据库,在数据处理和存储服务领域扮演着重要角色。其存储原理基于Google Bigtable设计思想,融合了HDFS的分布式存储能力,形成了独特的层次化结构。本文将通过三张核心示意图,直观解析HBase如何高效管理海量数据。
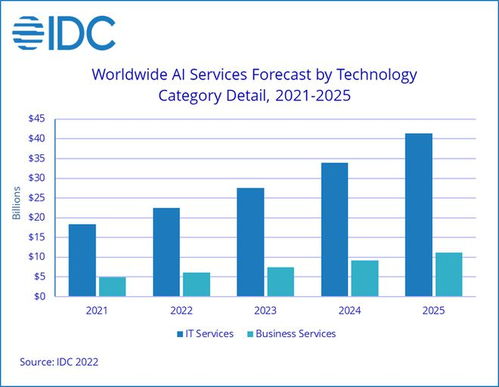
图一:HBase在Hadoop生态系统中的位置
HBase构建于HDFS之上,如同大厦的地基与楼层关系。HDFS提供底层可靠存储(数据块分布式存放),而HBase则在其上构建结构化存储服务:
- 数据持久化:所有HBase数据最终以HFile格式存储在HDFS中
- 元数据管理:通过ZooKeeper协调RegionServer状态与元数据操作
- 读写分离:写操作先写入Write-Ahead Log (WAL)和MemStore,再刷写到HDFS;读操作可合并MemStore和HFile数据
这张图清晰展示了HBase如何利用Hadoop生态组件实现高可靠、可扩展的存储基础。
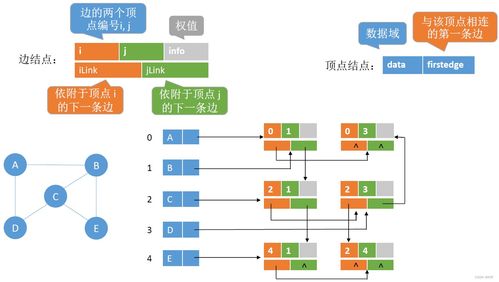
图二:HBase的逻辑存储模型——Sorted Map of Maps
HBase的数据模型可理解为多维有序映射表:
- 行键(RowKey):数据检索主键,按字典序排列,决定数据分布
- 列族(Column Family):物理存储单元,同族数据集中存放(图中展示CF1、CF2)
- 列限定符(Column Qualifier):动态列标识,支持稀疏存储
- 时间戳(Version):多版本数据标识,默认保留最新版本
示意图中,数据按RowKey横向切分为多个Region,每个Region内数据按列族独立存储。这种设计使得:
- 查询时可通过RowKey快速定位Region
- 同列族数据集中压缩,提升存储效率
- 支持数亿列的海量稀疏表存储
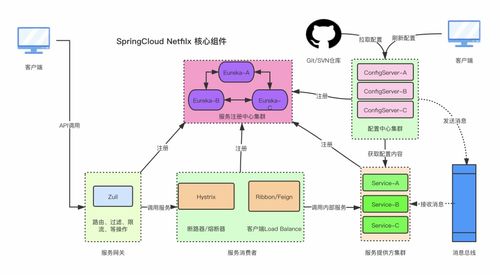
图三:HBase物理存储架构——RegionServer与StoreFile
这是最关键的存储实现图,展示数据在RegionServer中的物理组织:
- Region分割:每张表按RowKey范围划分为多个Region,分配到不同RegionServer
- Store结构:每个Region包含多个Store(对应列族),每个Store包含:
- MemStore:内存写缓冲区,排序后数据
- StoreFile:磁盘存储文件(HFile格式),由MemStore刷写生成
- Compaction机制:
- Minor Compaction:合并多个小StoreFile
- Major Compaction:合并所有StoreFile并清理过期数据
图中箭头清晰展示了数据流向:
- 写入路径:Client → WAL → MemStore → 定期刷写为StoreFile
- 读取路径:Client → MemStore + StoreFiles → 合并返回结果
- 压缩流程:多个StoreFile → 合并为更大StoreFile → 减少IO开销
数据处理服务的关键特性
基于上述存储原理,HBase提供三大核心服务能力:
- 强一致性读写
- 单行事务保证原子性
- 通过RegionServer主节点协调数据访问
- WAL机制确保写入不丢失
- 自动分片与负载均衡
- Region达到阈值时自动分裂
- Master服务监控并平衡Region分布
- 支持在线扩展,无需停机
- 高效数据生命周期管理
- TTL(生存时间)自动清理过期数据
- 多版本数据保留策略配置
- Bloom Filter加速不存在键的判断
存储优化实践建议
- RowKey设计策略
- 避免单调递增,采用散列前缀防止热点
- 将查询维度前置,利用字典序优化范围查询
- 长度控制在10-100字节,减少存储开销
- 列族配置要点
- 数量不宜过多(通常2-3个),每个列族独立存储
- 根据访问模式设置不同压缩算法(SNAPPY/LZ4)
- 合理设置内存缓存优先级
- 集群部署考量
- RegionServer与DataNode协同部署,减少网络传输
- 预留20%磁盘空间供Compaction使用
- 监控StoreFile数量,触发阈值告警
通过这三张图,我们完整理解了HBase如何将逻辑数据模型映射到物理存储:从HDFS基础存储,到Region分布式管理,再到MemStore与StoreFile的读写优化。这种层次化设计使得HBase能够支撑从千万到百亿级数据量的实时读写场景,成为大数据存储领域不可或缺的基础服务。
掌握这些核心原理后,在实际应用中还需结合具体业务特点调整配置参数,并通过监控系统持续观察Region分布、Compaction频率等关键指标,才能充分发挥HBase在数据处理和存储服务中的强大能力。