在移动互联网高速发展的时代,数据已成为企业核心的资产与竞争力。对于拥有数亿用户的vivo而言,如何高效、稳定地处理与存储海量的基础数据,是支撑其业务创新、用户体验优化和智能决策的关键。vivo通过构建一套先进、弹性且可靠的基础数据计算架构,在数据处理与存储服务领域积累了丰富的实践经验。
一、挑战:海量数据洪流下的核心诉求
vivo的业务场景多元,涵盖用户行为日志、设备状态信息、应用性能数据、交互事件等,每日产生的数据量达到PB级别。这些数据具有体积巨大、来源分散、格式多样、时效性要求高等特点。传统的单体式或分散式数据处理系统难以应对,主要面临三大挑战:
- 吞吐与实时性:需要同时满足批量离线计算的高吞吐和实时流计算的低延迟。
- 可靠与可扩展性:系统需具备高可用性,并能随着数据量的增长近乎线性地扩展。
- 成本与效率:在保障性能的前提下,必须优化存储与计算资源的使用效率,控制总体拥有成本。
二、架构核心:分层解耦与流批一体
为应对上述挑战,vivo构建了以“数据湖”为核心,融合“流批一体”计算范式的基础数据架构。整体架构分为以下几个层次:
1. 统一数据接入层:
建立标准化的数据采集与接入平台,兼容各类数据源(APP端、服务器日志、数据库Binlog等)。采用Apache Flume、Kafka等组件,实现数据的实时、准实时及批量接入,并进行初步的格式标准化与脏数据过滤,为下游提供统一的数据流。
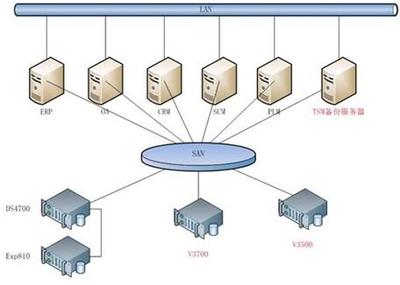
2. 弹性数据存储层(数据湖):
以HDFS和对象存储(如兼容S3协议)为基础,构建企业级数据湖。将原始数据、清洗后的数据、各层加工数据统一存储,打破数据孤岛。通过引入Apache Iceberg或Delta Lake等表格格式,在数据湖之上提供ACID事务、版本管理、schema演化等能力,使得海量数据存储兼具成本效益与查询效率。
3. 智能计算引擎层:
这是架构的“大脑”。vivo采用了“流批一体”的设计理念:
- 批量计算:基于Apache Spark构建强大的离线数据处理能力,用于T+1的报表、用户画像、数据仓库分层(ODS、DWD、DWS等)的构建。
- 流式计算:深度应用Apache Flink,处理实时点击流、监控告警、实时推荐等场景。通过Flink的精确一次(Exactly-Once)语义和状态管理,保障实时数据的准确性。
- “流批一体”实践:通过将业务逻辑抽象成统一的SQL或API,让同一套代码既能跑在Flink流模式上,也能跑在Spark批模式上,极大降低了开发维护成本,并保证了数据处理逻辑的一致性。
4. 统一服务与治理层:
构建了集中的元数据管理、数据血缘、数据质量监控和任务调度平台。例如,使用Apache Atlas进行数据资产管理,用DolphinScheduler或Airflow进行工作流编排。这一层确保了数据的可发现、可信、可用,是数据资产化的保障。
三、存储服务实践:分级存储与智能缓存
针对海量数据的存储,vivo实施了精细化的策略:
- 热温冷数据分级:根据数据的访问频率和时效性,将数据自动迁移至性能型SSD、容量型HDD以及成本更低的归档存储中,实现存储成本与访问性能的最佳平衡。
- 索引与加速:对常用查询字段建立高效的索引(如利用Hudi的索引能力),并引入Alluxio等内存加速层,为交互式查询和实时计算提供高速缓存。
- 多副本与纠删码:对核心热数据采用多副本机制保障高可用;对温冷数据采用纠删码(Erasure Coding)技术,在保证可靠性的同时显著提升存储空间利用率。
四、应用成效与未来展望
通过这套架构的落地实践,vivo取得了显著成效:数据处理链路时效性从小时级提升到分钟级甚至秒级;资源利用率平均提高30%以上;数据开发效率因“流批一体”而大幅提升。更重要的是,它为AI训练、精准营销、风控安全、用户体验优化等上层应用提供了坚实、高效的数据底座。
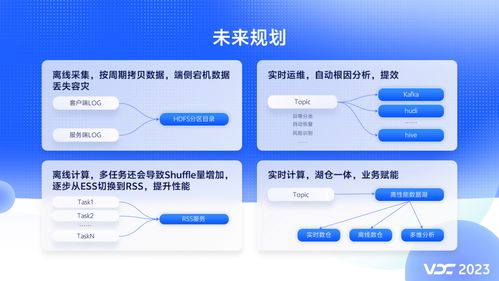
vivo将继续探索云原生计算架构(如Kubernetes上运行Flink/Spark)、存算分离的更深层次实践、以及AI for Data(利用AI优化数据治理与管理)等方向,让基础数据计算架构更智能、更弹性、更普惠,持续驱动业务价值的创造。
vivo的实践表明,面对海量数据,一个设计优良、贴合业务且持续演进的计算与存储架构,不仅是技术工程问题,更是企业数字化转型的核心引擎。